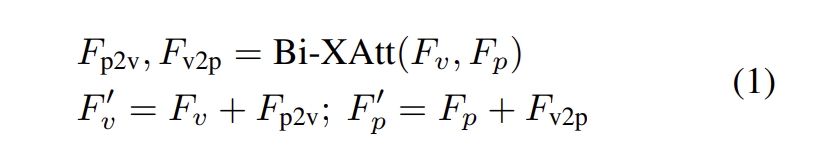Universal Instance Perception as Object Discovery and Retrieval
#
All instance perception tasks aim at finding certain objects specified by some queries such as category names, language expressions, and target annotations, but this complete field has been split into multiple independent subtasks. In this work, we present a universal instance perception model of the next generation, termed UNINEXT. UNINEXT reformulates diverse instance perception tasks
into a unified object discovery and retrieval paradigm and
can flexibly perceive different types of objects by simply
changing the input prompts.
Most current instance perception methods are developed for only a single or a part of
sub-tasks and trained on data from specific domains.
Such philosophy leads to drawbacks as follow:
Independent designs hinder models from learning and sharing generic knowledge between different tasks
and domains, causing redundant parameters.
The possibility of mutual collaboration between different tasks is
overlooked. For example, object detection data enables
models to recognize common objects, which can naturally
improve the performance of REC and RES.
Restricted
by fixed-size classifiers, traditional object detectors are hard
to jointly train on multiple datasets with different label vocabularies and to dynamically change object categories to detect during inference .
Since essentially all instance perception tasks aim at finding certain objects according to some queries, it leads to a
natural question: could we design a unified model to solve
all mainstream instance perception tasks once and for all?
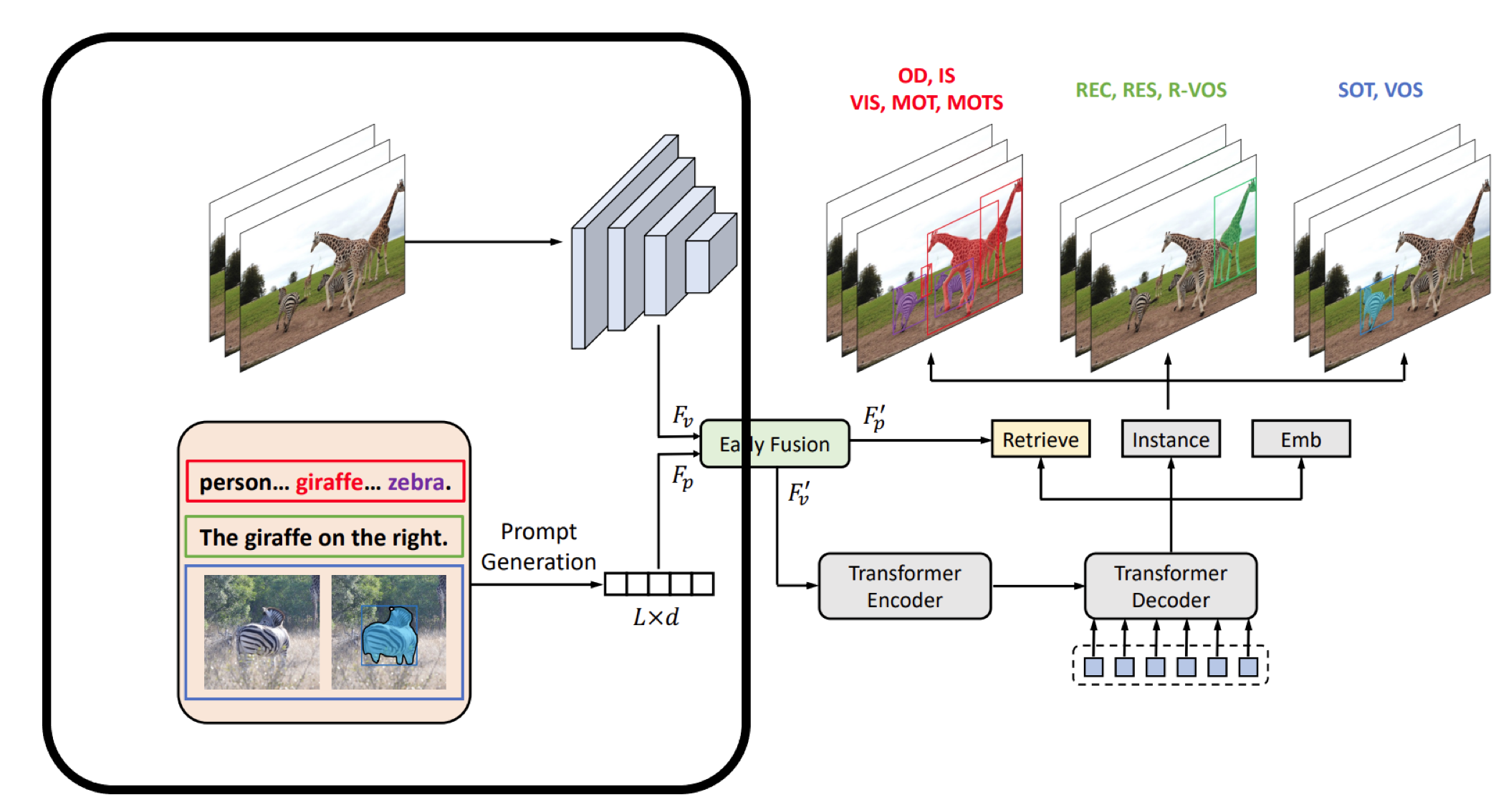
We propose a unified prompt-guided formulation for
universal instance perception, reuniting previously
fragmented instance-level sub-tasks into a whole. Benefits:
enormous data from different
tasks and label vocabularies can be exploited for jointly
training general instance-level representations, which is especially beneficial for tasks lacking in training data.
the unified model is parameter-efficient and can save redundant computation when handling multiple tasks simultaneously.
Benefiting from the flexible object discovery and retrieval paradigm, UNINEXT can train on different
tasks and domains, in no need of task-specific heads.
UNINEXT achieves superior performance on 20 challenging benchmarks from 10 instance perception tasks
using a single model with the same model parameters.
Retrieval by Category names includes object detection and instance segmentation. Two tasks that are fundamental to instance perception tasks.
Object Detection Methods:
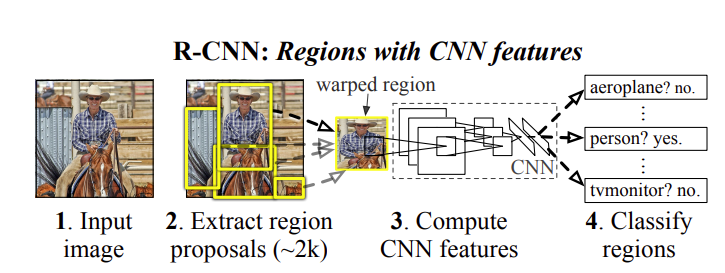
Two-stage method: First generate regions of interest (RoIs) and then classify each RoI into a specific category.RCNN
(🖱️Clike here to read RCNN explained) in 2014 is a two-stage method.
One-stage method: directly predict the category or the category score for each pixel or anchor. “End to End Object Detection with Transformers” is a one-stage method proposed in 2020.
RCNNs, YOLO, DETR(detection transformer)etc. are methods with a box-level detectors, which output a list of bounding boxes along with class labels and confidence scores, indicating the likelihood that each box contains an object of the specified class.
Methods for Video Tasks: Online “Detection then Association” Paradigm: Mainstream approach for MOT. Offline Fashion for VIS: These tasks use shorter video clips, videos are processed before making decision. The offline methods perform well on simpler benchmarks but struggle on more challenging ones.
REC: Referring Expression Comprehension. Given an image and a language expression, the model is required to find the object referred to by the expression.
RES: Referring Expression Segmentation. Given an image and a language expression, the model is required to segment the object referred to by the expression.
R-VOS: Referring Video Object Segmentation. Given a video and a language expression, the model is required to segment the object referred to by the expression in each frame.
For REC methods is more like a classification task, using one-stage, two-stage and transformer-based methods.
RES approaches focus more on designing
diverse attention mechanisms to achieve vision-language
alignment.
Current SOTA methods for R-VOS are Transformer-based and process the
whole video in an offline fashion. However, the offline
paradigm hinders the applications in the real world such as
long videos and ongoing videos
Single Object Tracking(SOT): Given a video and a bounding box annotation or mask annotation, the model is required to track the object in the video.
Video Object Segmentation(VOS): Given a video and a bounding box annotation or mask annotation, the model is required to segment the object in each frame. Problems and Solutions:
hard to Extract Informative Features: Most SOT methods encode information by passing a template to siamese backbone.While VOS approaches usually pass multiple previous frames
together with corresponding mask results to a memory encoder for extracting fine-grained target information.
Fusing Information: correlations are eraly adopted in SOT but suffer from information loss problems. Transformer-based methods are capable of finding more discriminative features. Besides, fusion for VOS is dominated by space-time memory networks (on papers with code✔️).
- Siamese Backbone with a Template for SOT - Memory Encoder with Previous Frames for VOS
- Hard to Extract Informative Features - Fusing Information: Early methods used correlations, now moving to Transformers for SOT; Dominated by space-time memory networks for VOS
MuST,INTERN,Unified-IO and OFA propose unified learning paradigm for different tasks. the commonality and inner relationship among different tasks are less explored and exploited.
MuST: A multi-task self-training approach for 6 vision tasks.
INTERN: Introduces a continuous learning scheme and shows strong generalization on 26 popular benchmarks.
Unified-IO and OFA: Propose a unified sequence-to-sequence framework for various vision, language, and multi-modal tasks.
Before introducing detailed methods, we first categorize
existing instance perception tasks into three classes.
Object detection, instance segmentation, MOT,
MOTS, and VIS take category names as prompts to
find all instances of specific classes.
REC, RES, and R-VOS exploit an expression as the
prompt to localize a certain target.
SOT and VOS use the annotation given in the first
frame as the prompt for predicting the trajectories of
the tracked target.
The $Enc_L (Encoder_{Language})$ is a crucial component in the UNINEXT model designed for instance perception tasks. It serves the purpose of transforming diverse language-related prompts into a unified, standardized form that the model can process.
Input: Takes in language expressions as prompts. These can be either category names (e.g., “person, bicycle, …, toothbrush” for COCO dataset) or specific language expressions (e.g., “the man holding an umbrella”).
Output: Produces a prompt embedding $F_p$ that is $d-dimensional$ and has a sequence length of $L$.
Annotation Encoder
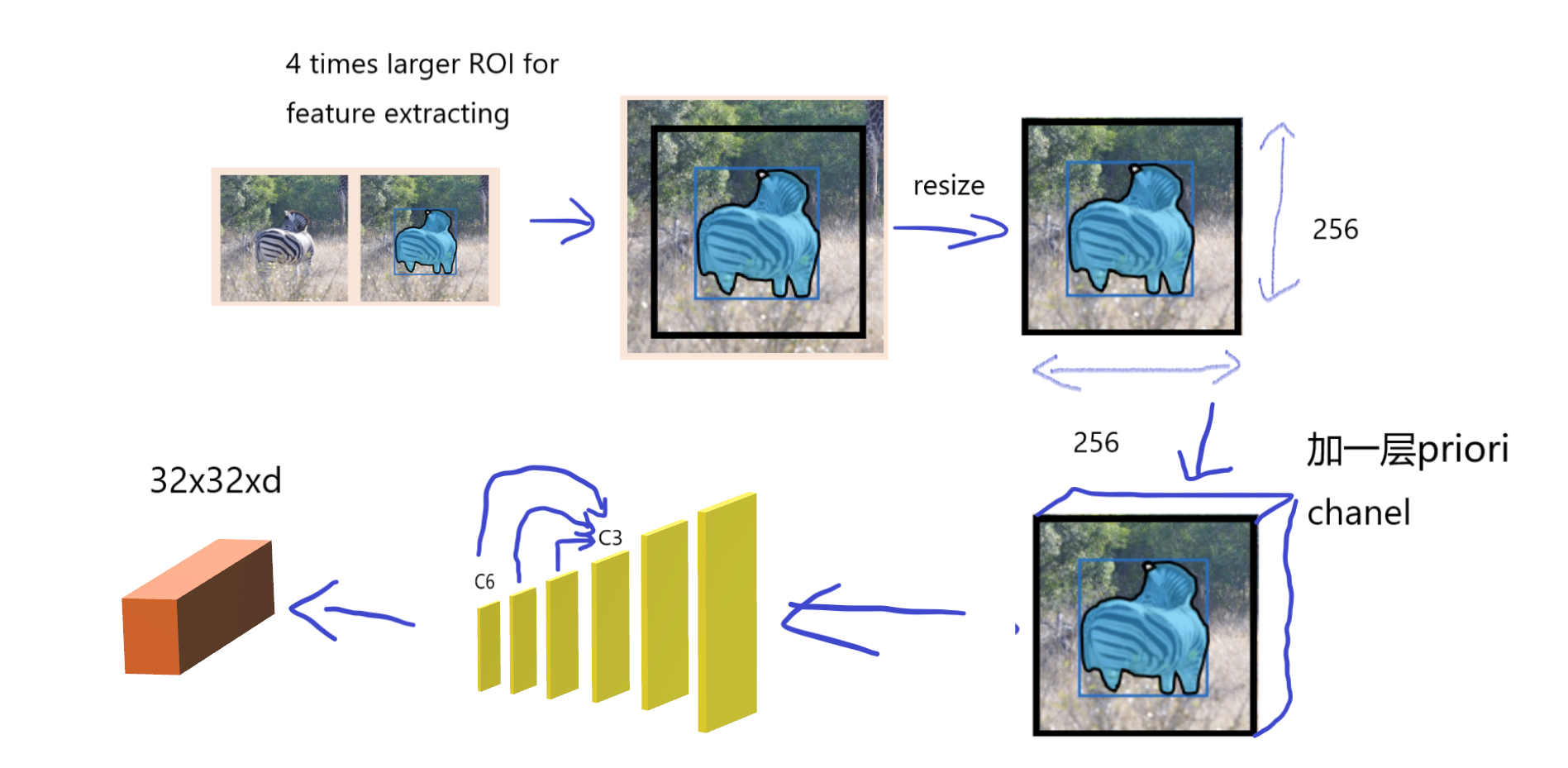
Input: Takes in the annotation of the first frame as the prompt. The annotation can be a bounding box or a segmentation mask.
Output: Produces a prompt embedding $F_p$ that is $d-dimensional$ and has a sequence length of $L$.
Procedure:
So the whole prompt generation is:
Task for next week:
To enhance the
original prompt embedding by the image contexts and to
make the original visual features prompt-aware, an early fusion module is adopted.
Bi-directional cross-attention module (Bi-XAtt) is used to retrieve information
Encoder input: $F_{p}’$ output: Stronger features $Fins ∈ R
_{N×d}$ 编码器的输出通常被称为嵌入(embedding)Method: Use Multi-scale Deformable Attention from DETR
Besides, as performed in two-stage Deformable
DETR [136], an auxiliary prediction head is appended at
the end of the encoder, generating N initial reference points
with the highest scores as the inputs of the decoder. (这里不懂)
With the help of the deformable attention, the object queries can efficiently retrieve prompt-aware visual features and learn strong instance embedding $Fins ∈ R
_{N×d}$